In April 2026, Andrej Karpathy (OpenAI co-founder, former Tesla AI Director) published a GitHub Gist called "LLM Wiki." It got 5,000+ stars within days. Not because it was technically impressive. Because it was surprisingly simple.
The premise: instead of building a RAG pipeline with embeddings and vector search, you have Claude Code maintain a structured collection of markdown files. You dump in raw sources. Claude organizes them. You ask questions. Claude searches its own index and answers with citations linking back to specific wiki pages.
Karpathy's own reaction was the most honest part: "I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files."
That's it. That's the idea. Here's how to build it.
Why RAG doesn't work well for personal notes
If you've ever set up a RAG pipeline for your own documents, you've probably hit this: the retrieval works fine for direct questions but falls apart on synthesis. Ask "what did that paper say about X?" and you get an answer. Ask "how does X relate to the patterns I've been noticing across the last three projects?" and you get something generic that ignores half of what's in your collection.
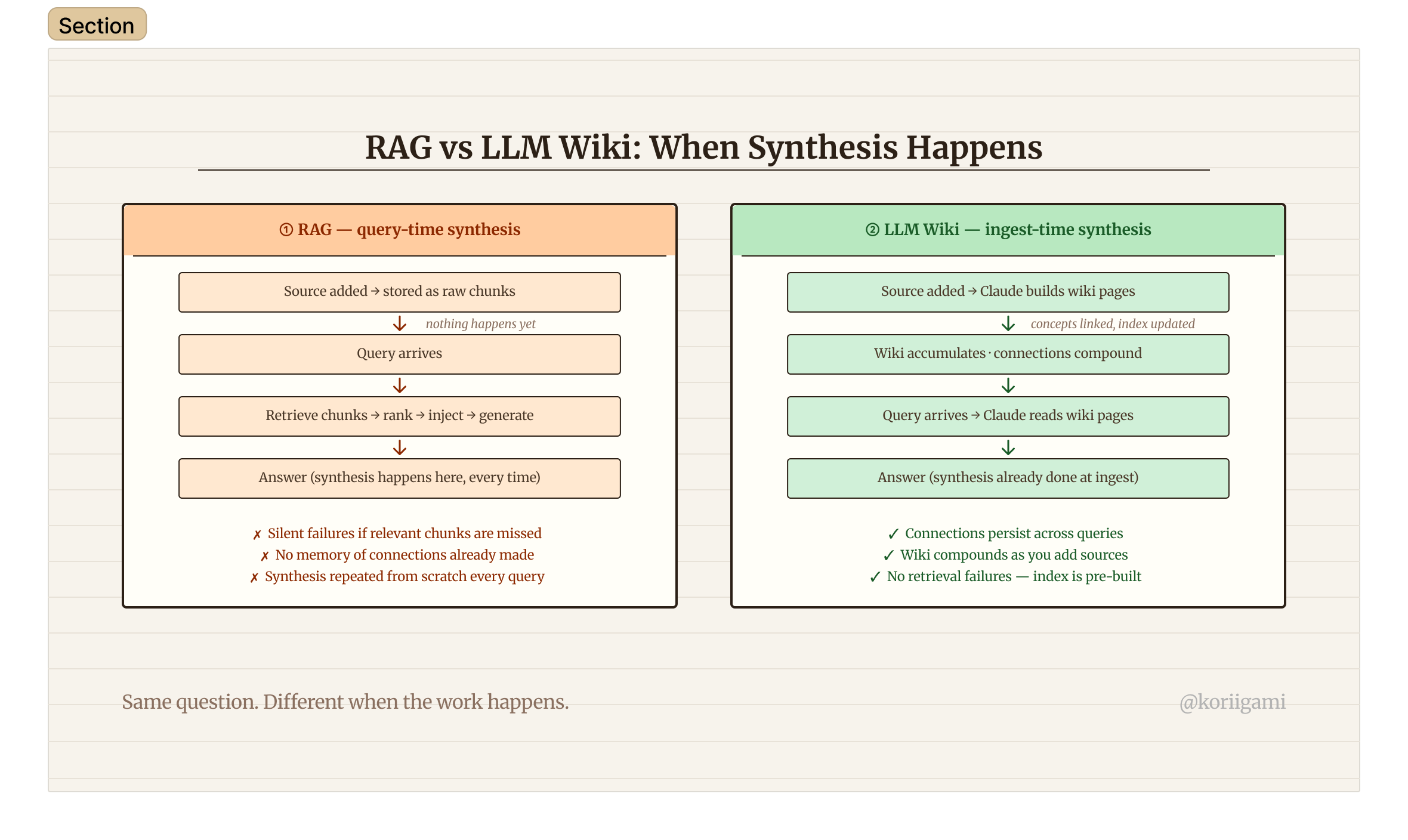
The reason is structural. RAG has no accumulation. Every query starts from scratch: retrieve, rank, inject into context, generate. If the answer requires synthesizing five documents, the system has to find all five, hope the retrieval worked, and stitch them together on the fly. There's no memory of connections you've already made, no building on earlier synthesis.
There's another problem with RAG that's underappreciated: retrieval failures are silent. The system doesn't tell you it didn't find the relevant chunk. It just generates a response without it, and you can't tell whether the answer is complete or missing something important.
For personal knowledge (your notes, your research, your patterns across projects), neither of these tradeoffs is acceptable. You want answers that reflect your actual context, not a best-effort retrieval pass.
The LLM wiki pattern: what it actually does differently
The core idea is simple once you see it. Instead of searching your notes at query time, you have Claude pre-process them into a structured wiki. Connections get made when you ingest a source, not when you ask a question. The wiki accumulates knowledge the way a notebook does, except Claude writes the notebook.
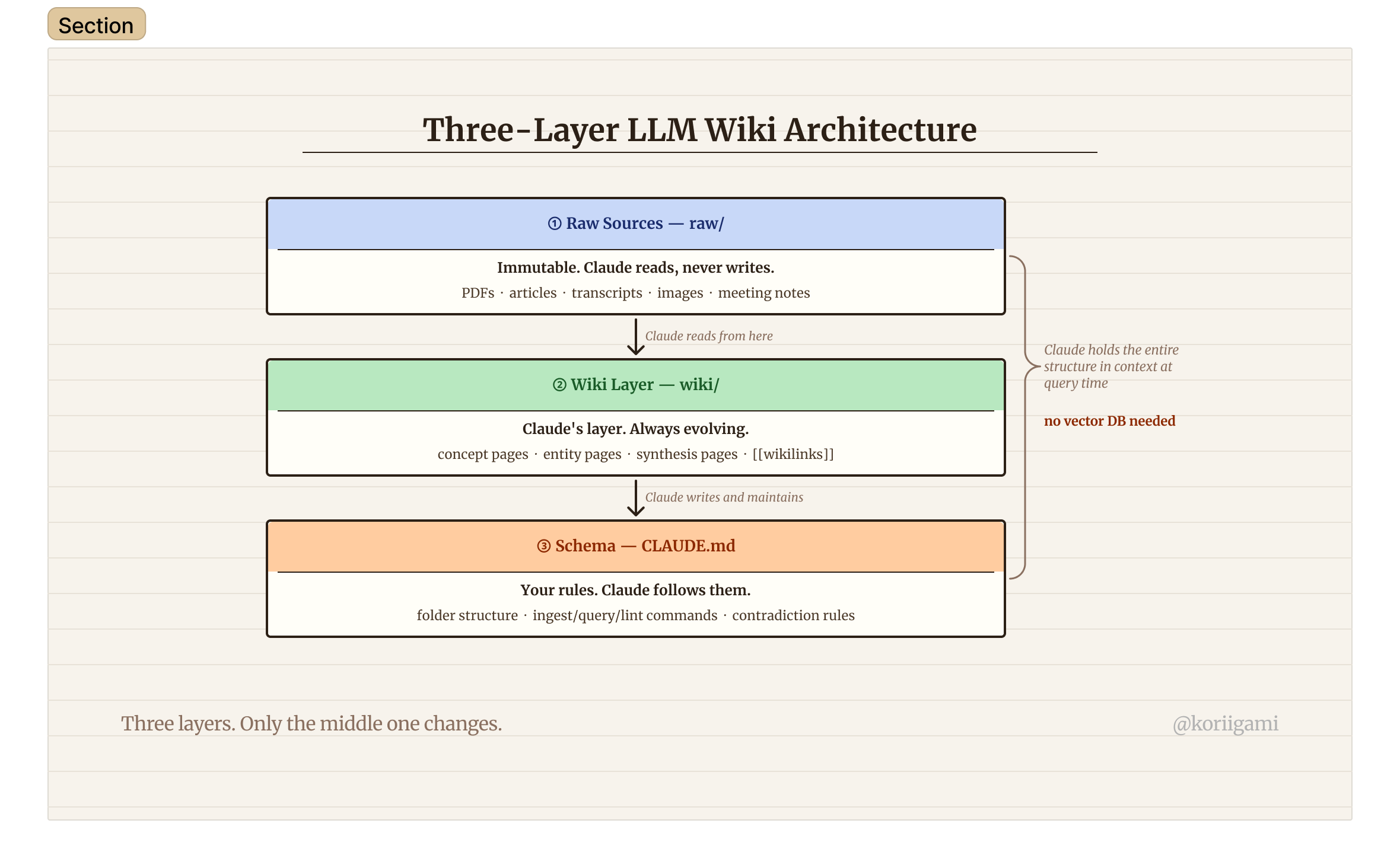
Three layers, each with a clear role:
Raw sources are immutable. PDFs, articles, transcripts, images, meeting notes: everything you feed the system. Claude reads from here but never writes to it. This is your record of what actually exists.
The wiki is Claude's layer. A directory of markdown files: concept pages, entity pages, comparison pages, synthesis pages. Claude creates and updates these as you ingest new sources. Each page links to others using [[wikilinks]]. Over time, the connections accumulate. Claude is responsible for maintaining them.
The schema is a CLAUDE.md file that tells Claude how the wiki works: what the folder structure is, what conventions to follow, what to do when it ingests a new source, how to handle contradictions between pages. If you've read my earlier piece on CLAUDE.md, this is the same pattern: encode the rules once, let Claude follow them consistently.
The reason this works at personal scale is context. For knowledge bases under roughly 100,000 tokens (call it 500–1,000 average-length notes), Claude can hold the index in context and reason over it directly. No embeddings, no vector database, no infrastructure to maintain.
Three operations you'll use every day
Ingest
You found something worth keeping. An article, a paper, a set of notes from a meeting. You save it to your raw/ folder and tell Claude to ingest it.
Claude reads the source, creates or updates wiki pages (a summary page for the source itself, concept pages for any new ideas it introduces, entity pages for people or projects mentioned), and updates the index file so future queries can find it. Then it marks the source as processed.
The result: the source is in your collection, its key ideas are on wiki pages that link to each other, and the index knows it exists.
Query
You ask a question. Claude searches the wiki (starting with the index, pulling relevant pages) and answers with citations that link directly to specific wiki pages, not back to raw sources. Because the wiki pages already contain synthesis, the answers can reference connections across multiple sources without repeating that work.
This is the payoff. A question that would require RAG to stitch together five documents just requires Claude to read the wiki pages it already built when those documents came in.
Lint
The wiki gets messy over time. Dead links, orphan pages, contradictions between what you thought two years ago and what you know now, stale pages that reflect outdated understanding. You run lint and Claude checks for all of it, fixing what it can automatically and flagging what needs your attention.
This is what makes the system compound. Not just accumulating pages, but maintaining the quality of the connections between them.
How to set this up with Claude Code and Obsidian
This takes about 30 minutes to get running for the first time.
Step 1: Create your vault structure.
Create a folder for your wiki (~/wiki or wherever makes sense). Inside it:
wiki/
├── raw/ ← immutable sources go here
│ ├── articles/
│ ├── papers/
│ └── notes/
├── wiki/ ← Claude's markdown pages
├── index.md ← Claude maintains this automatically
└── CLAUDE.md ← your schema
If you want an Obsidian view, open Obsidian and point it at this folder as a new vault. Everything stays in plain markdown, with no lock-in.
Step 2: Write your CLAUDE.md schema.
This is the most important file. It tells Claude exactly how your wiki works. Start from Karpathy's original gist and adapt it, or use one of the community implementations as a starting point. nvk/llm-wiki and Ar9av/obsidian-wiki are both solid bases.
Your schema should define: what the folder structure means, how to name wiki pages, what sections every page should have, how to handle contradictions, and the exact commands for ingest/query/lint.
A minimal version for the ingest operation looks like:
## Ingest command
When I say "ingest [filename]":
1. Read raw/[filename]
2. Create wiki/[slug].md with: summary, key concepts, related pages
3. Update or create concept pages for any new ideas
4. Add entry to index.md
5. Mark source as processed in raw/ (add a .processed suffix or move to raw/done/)Step 3: Ingest your first sources.
Open Claude Code with your wiki folder as the working directory. It will read your CLAUDE.md automatically. Then:
ingest articles/that-paper-i-saved.pdf
Claude processes it, creates wiki pages, updates the index. Do this with a handful of sources to see the structure before you decide if you want to adjust anything.
Step 4: Ask your first question.
What have I captured about [topic]? Summarize the key patterns and link to the relevant wiki pages.
The first few times you do this, the wiki will be sparse and the answers limited. That's fine. The system compounds: the more you ingest, the more useful the queries become.
Step 5: Schedule a weekly lint.
Add a reminder to run lint once a week. Ten minutes of cleanup keeps the wiki useful as it grows. Without it, dead links accumulate and pages diverge from each other.
A few things to get right from the start
Keep raw sources immutable. The moment you let Claude edit source files, you lose track of what was original and what was generated. Raw files are your ground truth. Only the wiki layer gets modified.
Write the schema before you ingest anything. If you start ingesting without a schema, Claude will make up conventions on the fly and they'll be inconsistent. Twenty pages in, you'll be retrofitting structure to a mess. Write the CLAUDE.md first, even if it's minimal.
Don't index everything. RAG pipelines tempt you to throw everything in. The LLM wiki works best when you're intentional. If a source isn't worth reading again, it's not worth ingesting. The index quality matters more than the index size.
Know the scale limit. The approach works reliably below roughly 50,000–100,000 tokens of wiki content. For most personal knowledge bases, that's a long way off. When you approach it, you'll know; queries will start getting slower and less coherent. At that point, a hybrid approach with a retrieval layer makes sense.
Start small, then let it compound
The first instinct is to migrate your entire Notion or Roam database on day one. Don't. Start with five sources in one domain, a subject you're actively thinking about. Ingest them, query them, see how the wiki pages look.
The value of this system comes from time, not volume. A wiki with 50 deeply connected pages is more useful than a wiki with 500 loosely indexed ones. Ingest consistently. Lint regularly. Let Claude maintain the connections. That's the whole pattern.
Karpathy called it "surprisingly viable." After a few weeks with it running in the background, I'd say that's underselling it.